Descripción General #
STELA cuenta con un modelo de Múltiples Configuraciones, el cual permite crear y gestionar varias configuraciones de manera independiente dentro de un mismo proyecto.
Gracias a esto, tus automatizaciones pueden alternar entre diferentes entornos o perfiles de configuración durante el recorrido del robot utilizando el comando «Configuración».
El sistema de gestión se divide en dos grandes niveles:
Configuración Global: Parámetros fijos que se aplican a todas las configuraciones creadas para ese proyecto.
Configuraciones del Proyecto: Perfiles específicos que puedes crear, editar o eliminar según tus necesidades. Al crear un proyecto, STELA genera automáticamente una configuración «Por defecto» (Default), que quedará identificada como tal hasta que decidas cambiarla o adaptarla.
⚠️ Nota importante: Un proyecto puede tener múltiples configuraciones personalizadas, pero siempre debe conservar al menos una.
¿Cómo accedo a la configuración del proyecto? #
Para acceder al modal de gestión en STELA, sigue estos pasos:
-
Dirígete al proyecto específico que deseas configurar.
-
Busca el icono de tres puntos (
...) ubicado justo al lado del nombre del proyecto. -
Selecciona la opción «Configuración» para desplegar el modal de gestión.
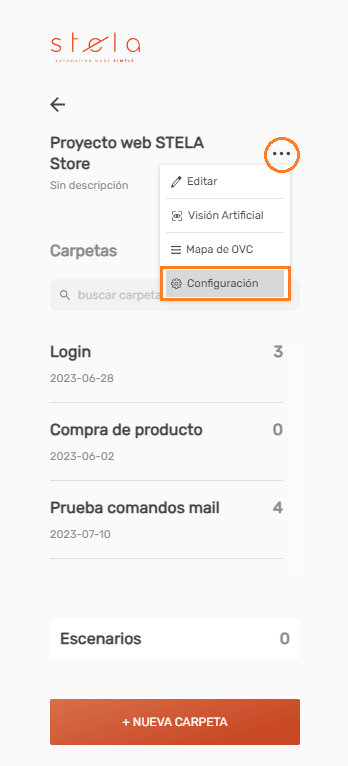
Al ingresar, verás las dos secciones principales dispuestas para su edición: Configuración Global y Configuraciones del Proyecto.
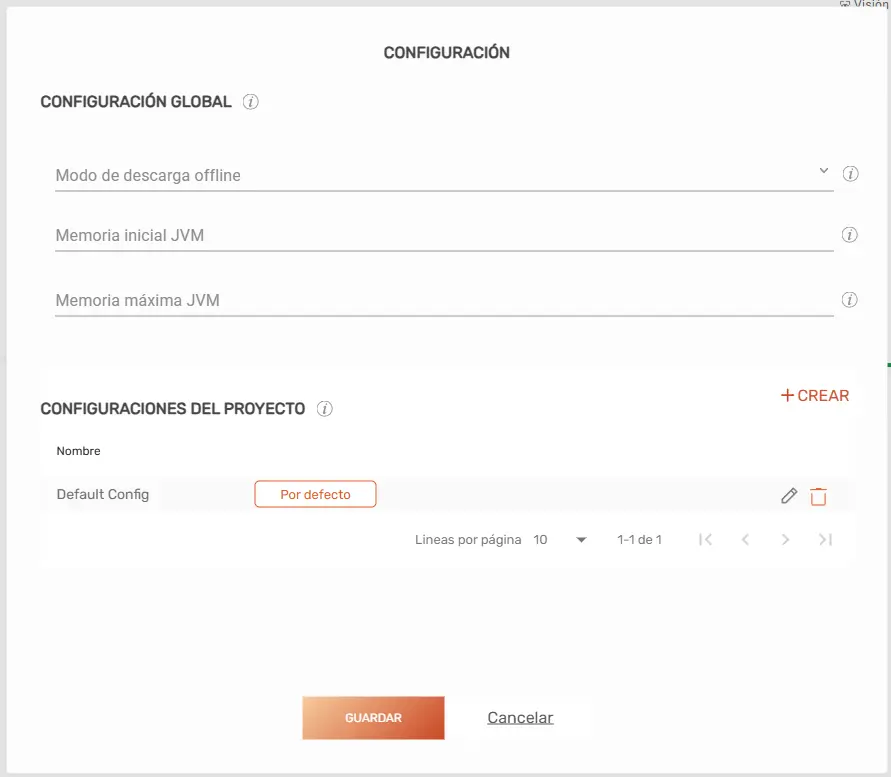
Configuración Global #
Estos elementos son transversales. Independientemente de la configuración del proyecto que elija el robot, estos valores siempre se mantendrán vigentes:
Modo de descarga Offline (Si/No): Indica si queremos activar las descargas para ejecuciones sin conexión a internet. Cuando está Activada, el robot de STELA no intentará conectarse al servidor. (Nota: Es posible que el robot deba descargarse nuevamente si existen actualizaciones de clave u otros cambios críticos en el servidor).
Memoria inicial JVM (#): Permite determinar la memoria inicial que utilizará la Máquina Virtual de Java (JVM) durante la ejecución.
Memoria máxima JVM (#): Permite determinar el límite máximo de memoria que la JVM podrá consumir en la ejecución.
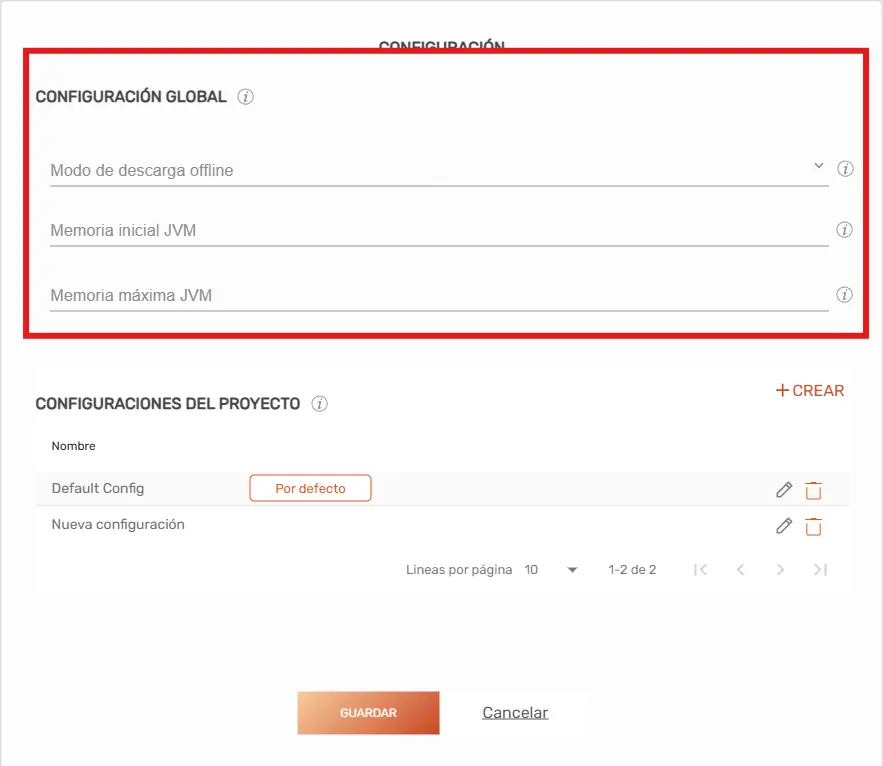
Configuraciones del Proyecto (Perfiles) #
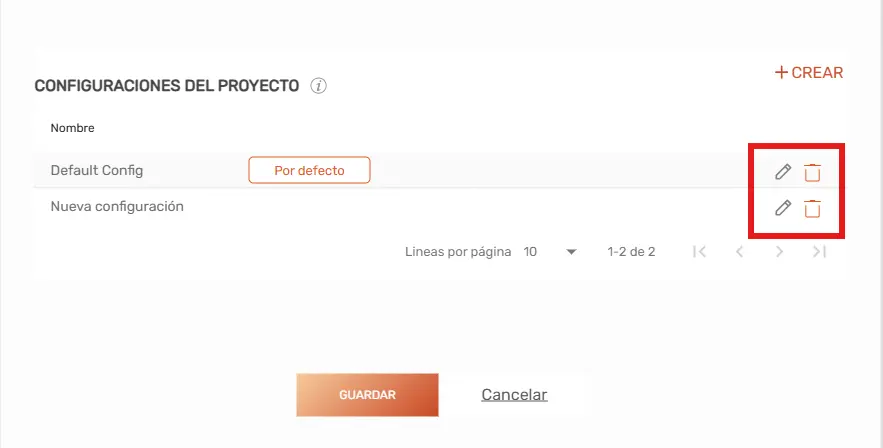
En esta sección del modal puedes gestionar los diferentes perfiles del proyecto. Para interactuar con ellos, utiliza los siguientes mandos:
- Crear una nueva configuración: Selecciona el botón «+ Crear».
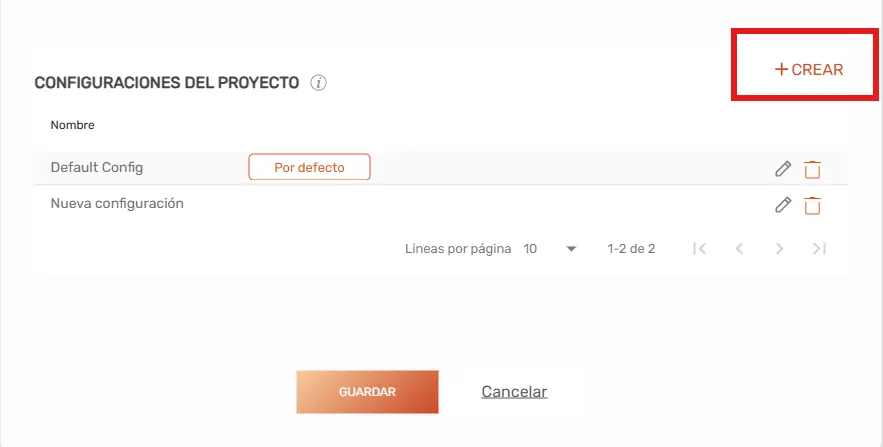
- Modificar una configuración existente: Haz clic en el icono del lápiz (Editar) al lado de la configuración correspondiente.
- Eliminar una configuración existente: Haz click en el ícono de Basura (Eliminar) al lado de la configuración correspondiente.
Al crear o editar una configuración de proyecto, se abrirá un segundo modal con opciones agrupadas en diferntes categorías.
Dentro del modal se podrá modificar el nombre o seleccionar a la configuración como «Por defecto».
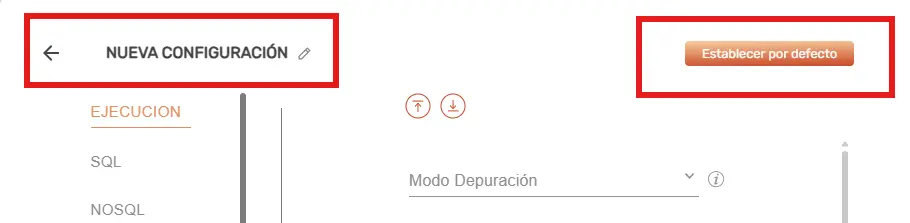
También se podrá Importar / Exportar la configuración de la categoría seleccionada.
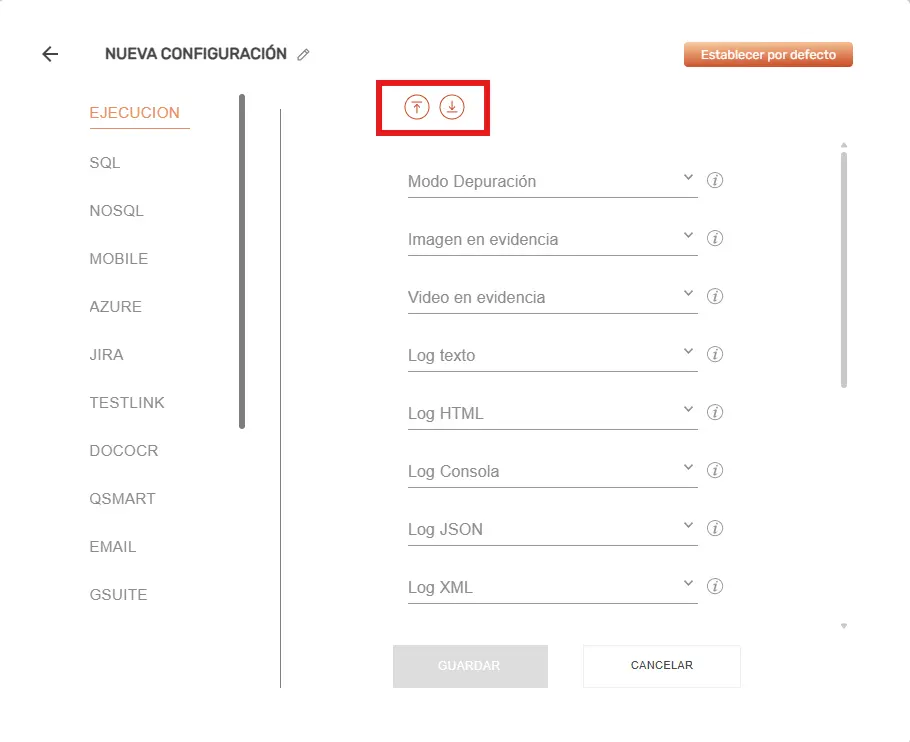
Se podrá recorrer el modal entre sus diferentes categorías (ubicadas a la izquierda del modal), y configurar sus diferentes elementos.
A continuación se explicará cada elemento configurable por cada categoría:
Ejecución #
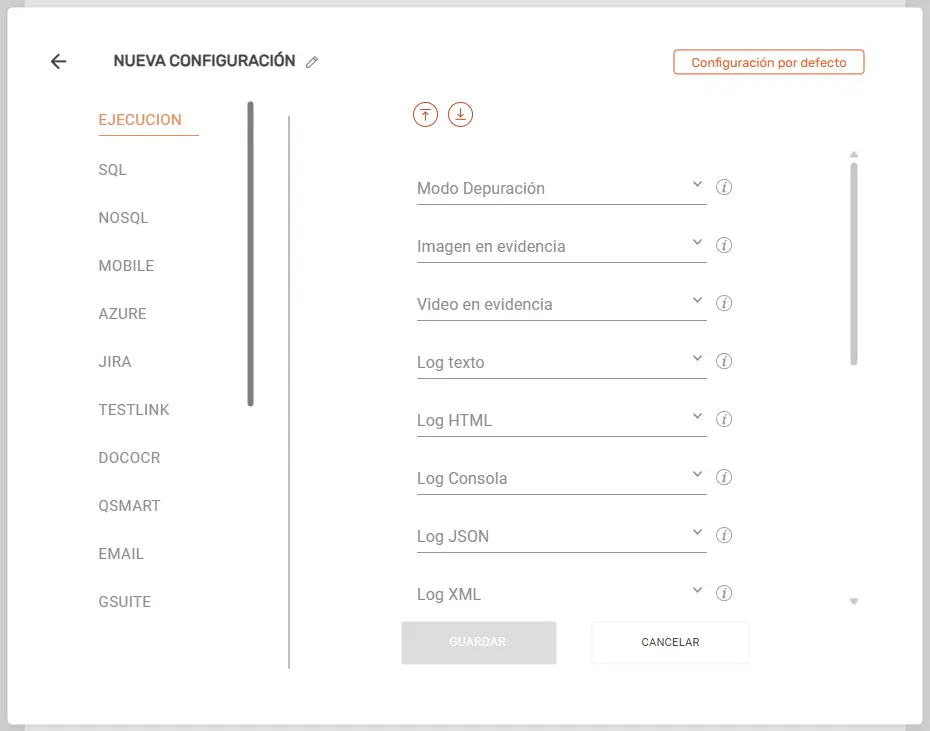
- Modo depuración (Si/No): Indica si queremos activar (o no) el modo depuración. Posibilita observar mayor cantidad de detalles en la consola de ejecución. Por defecto si el campo se deja vacío el modo de depuración no está activado.
- Imagen en evidencia (Si/No): Indica si STELA debe generar (o no) imágenes en las evidencias. Se sugiere dejar encendida; en robots de larga duración se puede apagar para minimizar el uso de memoria y disco. Por defecto, si el campo se deja vacío STELA genera imágenes en las evidencias.
- Video en evidencia (Si/No): Indica si STELA debe generar (o no) el video de evidencia al final de la ejecución para registrar las acciones visuales del robot. Por defecto, si el campo se deja vacío STELA genera el video de evidencia al final de la ejecución.
- Log Texto (Si/No): Indica si STELA debe generar (o no) un archivo de evidencia en formato de texto plano. Por defecto, si el campo se deja vacío STELA generará el archivo como parte de la evidencia.
- Log HTML (Si/No): Indica si STELA debe generar (o no) un archivo de evidencia formateado en HTML. Por defecto, si el campo se deja vacío STELA generará el archivo como parte de la evidencia.
- Log Consola (Si/No): Indica si STELA debe generar (o no) el registro de ejecución en la salida estándar de la consola. Por defecto, si el campo se deja vacío STELA dejará registro de la ejecución en la salida estándar.
- Log JSON (Si/No): Indica si STELA debe generar (o no) un archivo de evidencia estructurado en formato JSON. Por defecto, si el campo se deja vacío STELA generará el archivo como parte de la evidencia.
- Log XML (Si/No): Indica si STELA debe generar (o no) un archivo de registro estructurado en formato XML.
- Tiempo de espera por defecto (#): Permite definir en segundos el tiempo de espera estándar que utilizará STELA al realizar una acción (por ejemplo, esperar a que aparezca un objeto para hacer clic). Por defecto, si el campo se deja vacío el tiempo de espera de inicio de aplicación será de 300 segundos.
- Espera inicio aplicación (#): Permite definir cuánto tiempo, en segundos, STELA espera hasta que la aplicación objetivo se inicie.
- Ejecución headless de navegadores (Si/No): Indica si queremos activar (o no) la ejecución de los navegadores web en segundo plano, sin abrir la interfaz gráfica. Por defecto, si el campo se deja vacío la ejecución NO se hará en segundo plano / se hará abriendo la interfaz gráfica.
- JDK: Especifica la ruta de instalación en la máquina del motor JDK con el que se ejecuta la aplicación Java Swing a automatizar (esencial para automatizaciones SWING). Por defecto, si este campo se deja vacío utilizará el mismo JDK que se está usando para ejecutar el robot de STELA.
- Tiempo de espera API (#): Permite indicar la cantidad de segundos que un llamado a un servicio REST utilizando el comando API va a esperar por la respuesta. Por defecto, si el campo se deja vacío el tiempo de espera será de 60 segundos.
- Cerrar drivers (Si/No): Indica si queremos cerrar (o no) de forma automática los drivers de las aplicaciones al finalizar la ejecución. Por defecto, si el campo se deja vacío STELA procederá a cerrar los drivers de las aplicaciones al finalizar la ejecución.
- Procesamiento AI de HTML (Si/No): Indica si queremos activar (o no) el uso de Inteligencia Artificial para el reconocimiento avanzado de objetos en el código HTML. Por defecto, si el campo se deja vacío STELA utilizará el soporte de Inteligencia Artificial al reconocer objetos.
- Procesamiento AI de Imágenes (Si/No): Indica si queremos activar (o no) el uso de Inteligencia Artificial para reconocer objetos directamente en las imágenes. Por defecto, si el campo se deja vacío STELA utilizará el soporte de Inteligencia Artificial al reconocer objetos.
SQL #
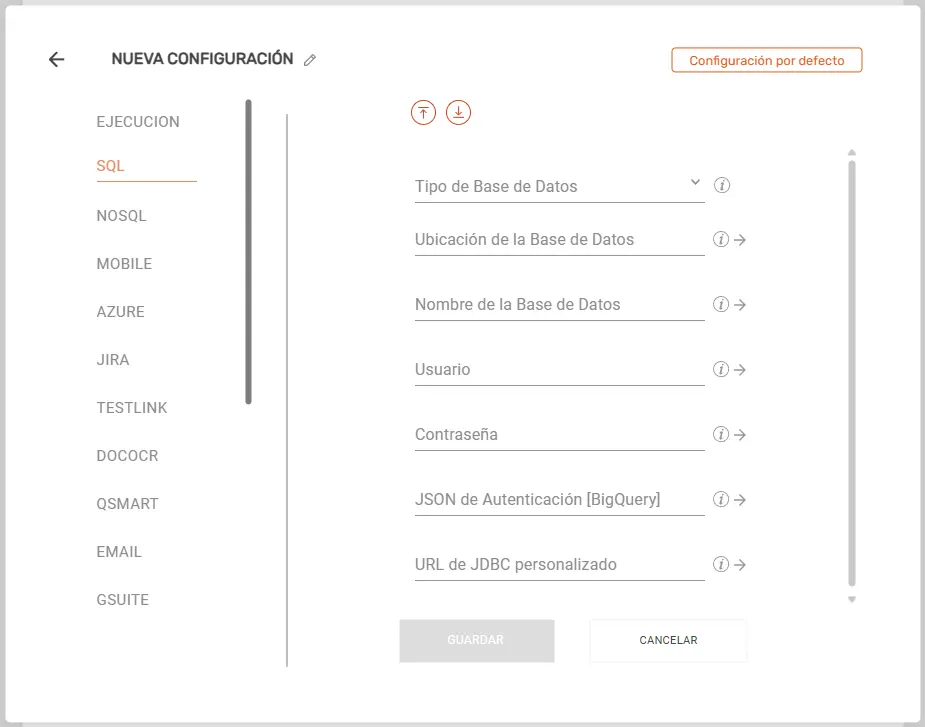
- Tipo de Base de Datos: Selecciona en el menú desplegable el motor correspondiente (
SQLSERVER,MYSQL,POSTGRESQL,BIGQUERY,MARIADB,ORACLE,FIREBIRDSQL,DB2oDB2AS400). - Ubicación de la Base de Datos: Ingresa el dominio o dirección IP junto con el puerto (Formato:
Dominio:Puerto) con la que se desea establecer la conexión. - Nombre de la Base de Datos (text): Escribe el nombre exacto de la base de datos a la que te vas a conectar.
- Usuario (text): Ingresa el nombre de usuario con permisos de acceso a la base de datos.
- Contraseña (text): Introduce la clave de acceso para el usuario indicado.
- JSON de Autenticación BigQuery: Pega el contenido completo del archivo JSON de credenciales proporcionado por Google Cloud (aplica solo para BigQuery).
- URL de JDBC personalizado: Introduce la cadena de conexión JDBC completa en caso de requerir parámetros de conexión avanzados o específicos.
NOSQL #
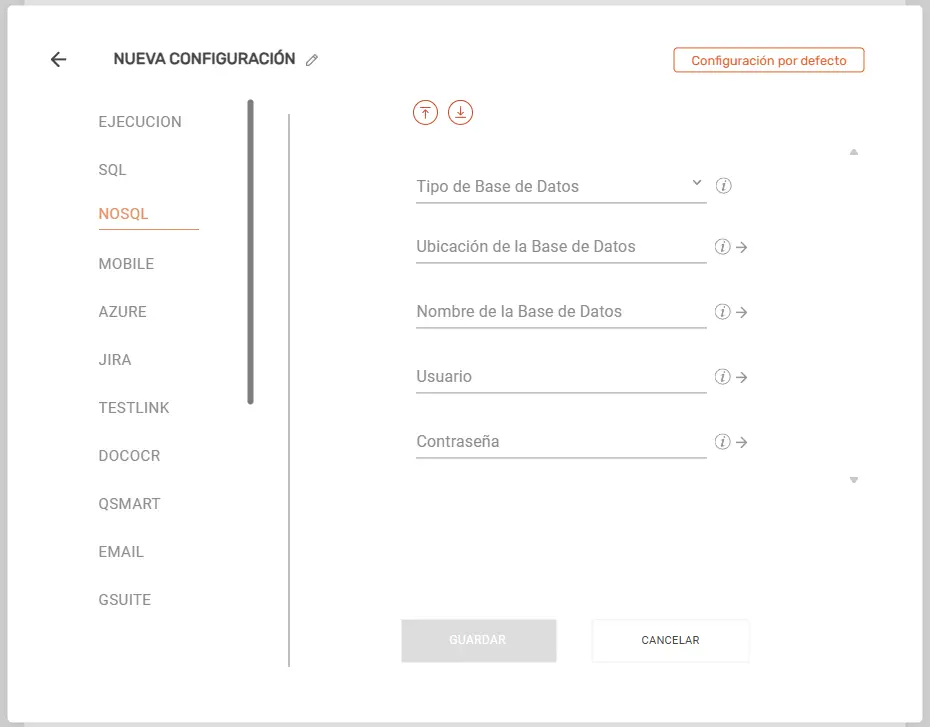
- Tipo de Base de Datos: Selector fijo para bases de datos no relacionales, configurado en
MONGODB. - Ubicación de la Base de Datos: Ingresa el dominio/IP y puerto del servidor de base de datos NoSQL.
- Nombre de la Base de Datos: Escribe el nombre de la base de datos NoSQL de destino.
- Usuario: Ingresa el usuario con privilegios de conexión en MongoDB.
- Contraseña: Introduce la contraseña correspondiente al usuario de MongoDB.
Mobile #
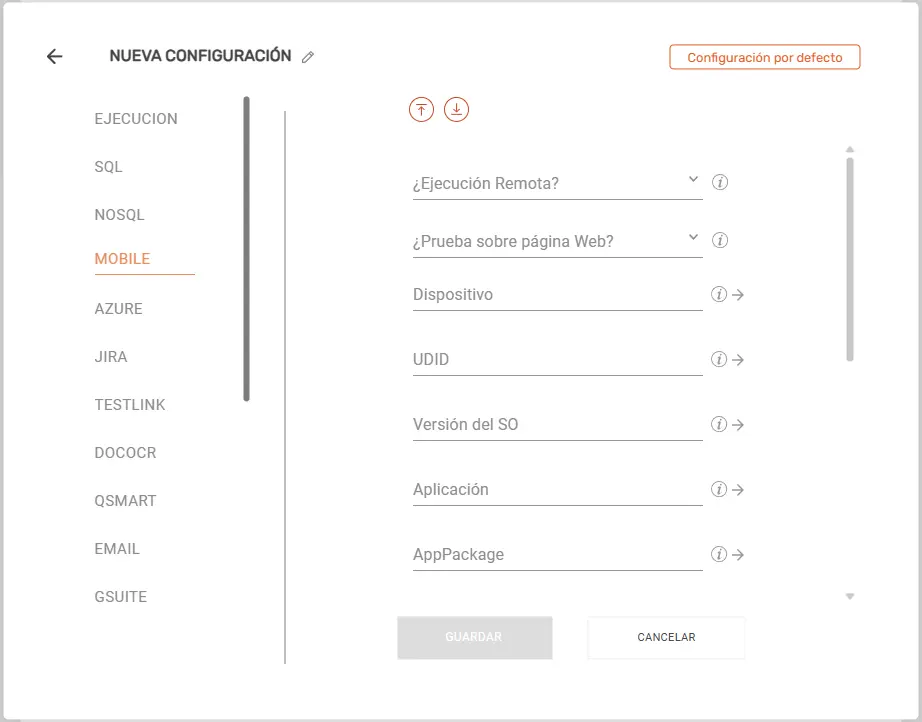
- ¿Ejecución Remota?: Elige el entorno de ejecución móvil seleccionando entre
NO,GCC,SAUCELABSoBROWSERSTACK. Por defecto, si este campo se deja vacío, STELA no permitirá la ejecución remota, la ejecución móvil se hará en un dispositivo de forma local. - ¿Prueba sobre página Web?: Define mediante
SIoNOsi la automatización móvil se realizará sobre un navegador web móvil o una app nativa/híbrida. Por defecto, si este campo se deja vacío el robot ejecutará sobre una app nativa / hibrida. - Dispositivo: Especifica el nombre comercial o modelo del dispositivo móvil a emular o testear.
- UDID: Escribe el identificador único físico del dispositivo móvil (Unique Device Identifier). Este campo es solo para robots que corren contra dispositivos iOS.
- Versión del SO: Indica la versión exacta del sistema operativo móvil (ej.
13.0,14.4). - Aplicación: Especifica la ruta del archivo binario de la aplicación (
.apkpara Android o.ipapara iOS) o su identificador en la nube. - AppPackage: Ingresa el paquete de Java exclusivo de la aplicación Android que deseas ejecutar.
- AppActivity: Describe la actividad de Android que se desea lanzar para iniciar la aplicación.
- Navegador: Indica el nombre del navegador móvil a utilizar en caso de pruebas web (ej.
Chrome,Safari). - NoReset (SI / NO): Selecciona si deseas mantener los datos de la aplicación y no resetear la sesión entre ejecuciones.
- Proyecto (Browserstack): Escribe el nombre del proyecto asignado en la plataforma de Browserstack.
- Build (Browserstack): Define el identificador o nombre de la compilación/build para agrupar las pruebas en Browserstack.
- TestName (Browserstack): Asigna el nombre específico con el que se registrará la prueba en el dashboard de Browserstack.
- Usuario (Browserstack, SauceLabs): Introduce tu nombre de usuario de la plataforma de pruebas en la nube elegida.
- Access Key (Browserstack, SauceLabs): Pega la clave de acceso privada (Token/API Key) de tu cuenta de Browserstack o SauceLabs.
Azure #
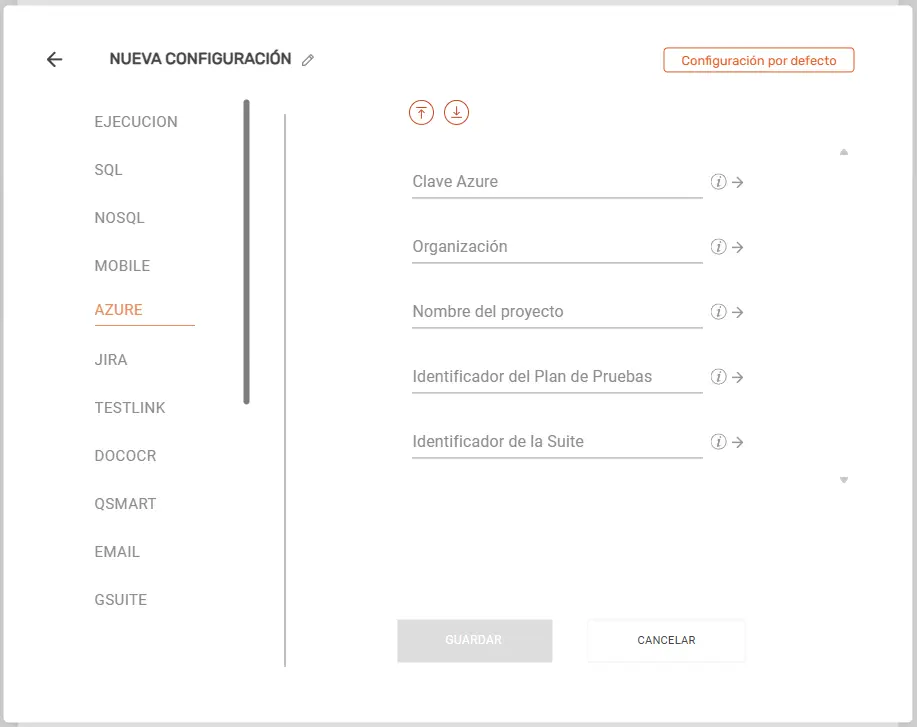
- Clave Azure: Introduce el token de acceso personal (PAT) o clave secreta de conexión con Azure DevOps.
- Organización: Escribe el nombre exacto de tu organización dentro de Azure DevOps.
- Nombre del proyecto: Especifica el nombre del proyecto en Azure donde se gestionan los planes de prueba.
- Identificador del Plan de Pruebas: Ingresa el ID numérico del Test Plan en Azure DevOps para reportar los resultados.
- Identificador de la Suite: Ingresa el ID numérico de la Test Suite específica dentro de tu plan de pruebas.
Jira #
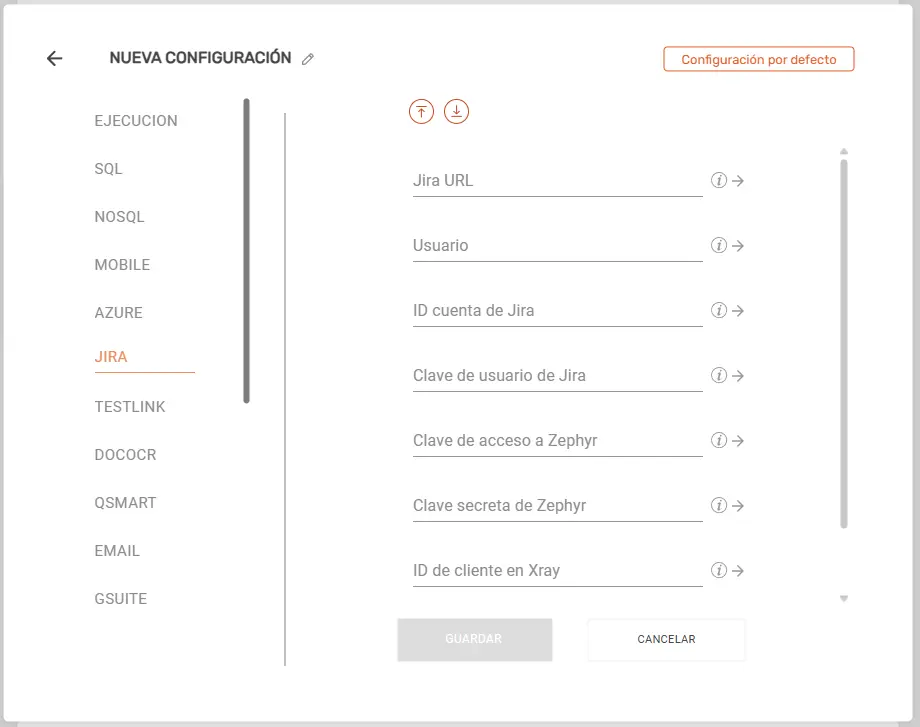
- Jira URL: Proporciona la dirección web base de tu instancia de Jira (ej.
https://tu-dominio.atlassian.net). - Usuario: Ingresa el correo electrónico o nombre de usuario asociado a la cuenta de Jira.
- ID cuenta de Jira: Introduce el identificador único de cuenta (Account ID) provisto por Atlassian.
- Clave de usuario de Jira: Ingresa el API Token generado desde tu cuenta de Atlassian para la autenticación.
- Clave de acceso a Zephyr: Introduce la clave de acceso API requerida para la integración con Zephyr.
- Clave secreta de Zephyr: Introduce la clave secreta generada en Zephyr para validar la conexión.
- ID de cliente en Xray: Pega el identificador de cliente (Client ID) para la autenticación de la API de Xray.
- Clave secreta de Xray: Pega la contraseña secreta (Client Secret) generada en Xray para la API de sincronización.
Testlink #
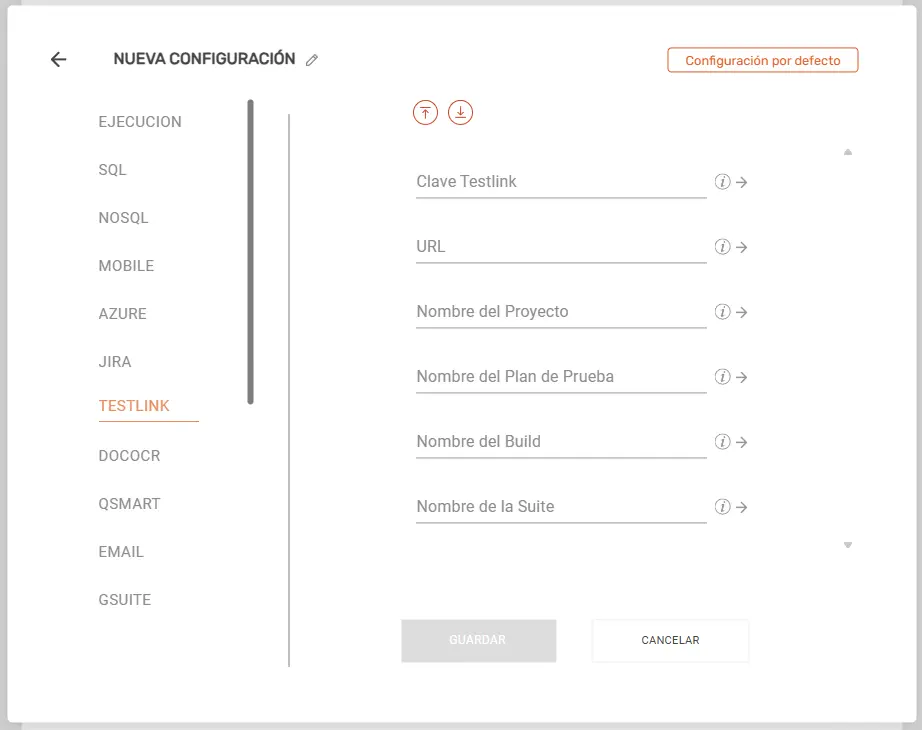
- Clave Testlink: Introduce la clave de desarrollador (API Token) generada en tu perfil de TestLink.
- URL: Proporciona la dirección URL completa del endpoint XML-RPC de tu servidor TestLink.
- Nombre del Proyecto: Escribe el nombre tal cual del proyecto de pruebas en TestLink.
- Nombre del Plan de Prueba: Indica el nombre del Plan de Pruebas activo donde se reportarán los resultados.
- Nombre del Build: Especifica la versión o Build creada dentro de tu Plan de Pruebas de TestLink.
- Nombre de la Suite: Especifica la suite de pruebas asociada a los casos de test automatizados.
DOCOCR #
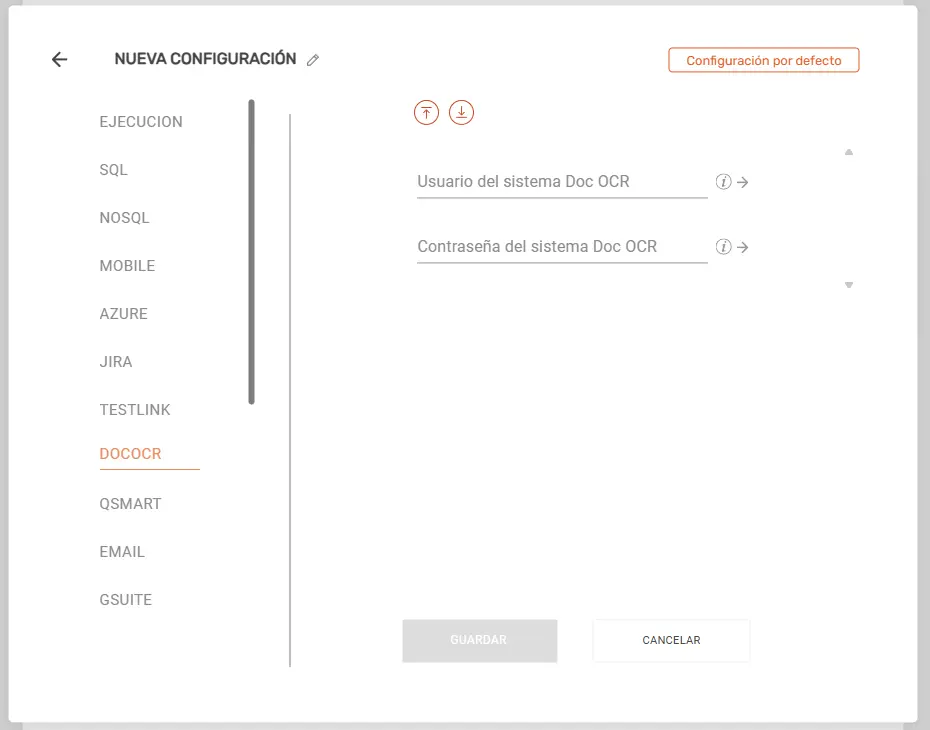
- Usuario del sistema Doc OCR: Introduce el nombre de usuario asignado para autenticarse en la plataforma Doc OCR.
- Contraseña del sistema Doc OCR: Ingresa la contraseña correspondiente para el acceso al servicio Doc OCR.
QSMART #
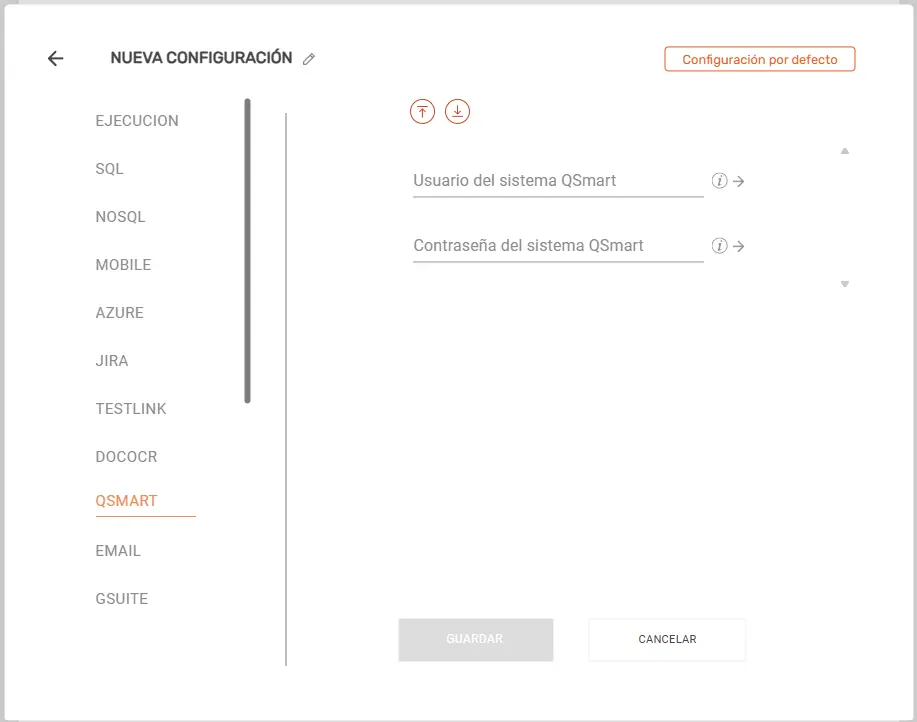
- Usuario del sistema QSMART: Introduce el identificador o usuario de acceso para el ecosistema QSMART.
- Contraseña del sistema QSMART: Ingresa la clave de acceso vinculada al usuario de QSMART.
Email #
- Host SMTP: Especifica la dirección del servidor de salida de correo (ej.
smtp.gmail.com). - Puerto SMTP: Ingresa el número de puerto para el envío de correos (ej.
465o587). - Protocolo de Inbox: Define el protocolo para la lectura de la bandeja de entrada (
IMAPoPOP3). - Host IMAP/POP3: Proporciona la dirección del servidor de entrada de correo (ej.
imap.gmail.com). - Puerto IMAP/POP3: Ingresa el número de puerto para la lectura de correos (ej.
993para IMAP). - Email: Introduce la dirección de correo electrónico institucional o de sistema que usará el robot.
- Contraseña: Introduce la contraseña de la cuenta o la contraseña de aplicación específica.
- Usuario: Especifica el nombre de usuario de la cuenta de correo (frecuentemente coincide con la dirección de email).
- Credencial OAuth2: Asocia una cuenta OAuth2 que el proyecto tenga disponible. Las cuentas OAuth2 se pueden dar de alta y asignar al proyecto desde el Panel de Administración.
Gsuite #
- Credenciales cuenta de servicio: Adjunta o pega el contenido estructurado del archivo JSON perteneciente a la cuenta de servicio de Google Cloud.
- Credenciales OAuth2: Introduce el ID de cliente y secreto de cliente para flujos de autenticación OAuth2 de Google Workspace.
AWS #
- Clave de acceso AWS S3: Introduce el ID de la clave de acceso (Access Key ID) de tu usuario de IAM en Amazon Web Services.
- Clave secreta AWS S3: Introduce la clave de acceso secreta (Secret Access Key) vinculada a AWS.
- Región: Selecciona el código identificador de la región geográfica de AWS donde está tu bucket S3 (ej.
us-east-1).
AzureOCR #
- Endpoint: Proporciona la URL base del recurso de Azure Cognitive Services / Azure AI Vision.
- Modelo: Especifica la versión o variante del modelo de extracción de texto a emplear.
- API Version: Indica la versión de la API de Azure a la que apuntarán las peticiones (ej.
2023-07-31). - Clave de subscripción: Pega la clave API (Key 1 o Key 2) generada en el portal de Azure para este recurso.
SSH #
- Host SSH: Introduce la IP o nombre de dominio del servidor remoto al que se conectará el robot por SSH.
- Puerto SSH: Especifica el puerto de conexión (por defecto es el
22). - Usuario SSH: Escribe el nombre de usuario con credenciales en la máquina remota.
- Contraseña SSH: Introduce la contraseña de autenticación para el usuario mencionado.
- Clave privada SSH: Pega el contenido de la clave privada (archivo
.pemo.id_rsa) en caso de utilizar autenticación por par de claves.
ChatGPT #
- Clave de subscripción: Pega la API Key provista por OpenAI para consumir sus servicios.
- Endpoint: Define la URL de la API de OpenAI (o de tu proxy corporativo) para direccionar las solicitudes.
- Modelo: Ingresa el nombre técnico del modelo a consumir (ej.
gpt-4o,gpt-3.5-turbo). Si este campo queda vacío, STELA utilizará el modelo gpt-4o. - Temperatura: Ajusta el valor numérico (de
0a2) que controla la creatividad o aleatoriedad de la respuesta (valores bajos dan respuestas más deterministas). Por defecto, si el campo se deja vacío se asignará una temperatura de 1 a las consultas. - Tiempo de espera: Define en segundos el tiempo máximo de espera antes de que la petición al modelo expire. Por defecto, si el campo se deja vacío se utilizará un tiempo de espera de 60 segundos.
- Semilla: Especifica un número entero (seed) para intentar que las respuestas del modelo sean estables y reproducibles.
- Límite de respuesta: Determina el número máximo de tokens a generar en la respuesta del asistente. Por defecto, si el campo se deja vacío se asignarán 20 tokens como máximo a utilizar en la consulta.
Gemini #
- Clave de subscripción: Ingresa la API Key de Google AI Studio o Vertex AI para autenticar tus peticiones.
- Endpoint: URL del endpoint oficial del servicio de Google Gemini.
- Modelo: Especifica la versión exacta del modelo de Google (ej.
gemini-1.5-pro). Si este campo queda vacío, STELA utilizará el modelo gemini-2.5-flash-lite. - Temperatura: Modifica el coeficiente de aleatoriedad para las respuestas de la Inteligencia Artificial. Por defecto, si el campo se deja vacío se asignará una temperatura de 1 a las consultas.
- Tiempo de espera: Segundos máximos de tolerancia para recibir la respuesta del servidor de Google. Por defecto, si el campo se deja vacío se utilizará un tiempo de espera de 60 segundos.
- Límite de respuesta: Configura la restricción máxima de tokens de salida para controlar la extensión del texto devuelto. Por defecto, si el campo se deja vacío se asignarán 20 tokens como máximo a utilizar en la consulta.
Anthropic #
- Clave de subscripción: Proporciona la API Key emitida desde la consola de Anthropic.
- Endpoint: Dirección URL del servidor API de Anthropic.
- Modelo: Indica el nombre del modelo de lenguaje de la familia Claude (ej.
claude-3-5-sonnet). Si este campo queda vacío, STELA utilizará el modelo claude-haiku-4-5. - Temperatura: Configura la variabilidad y creatividad deseada en las respuestas de la IA. Por defecto, si el campo se deja vacío se asignará una temperatura de 1 a las consultas.
- Tiempo de espera: Tiempo máximo en segundos asignado para esperar la contestación del modelo. Por defecto, si el campo se deja vacío se utilizará un tiempo de espera de 60 segundos.
- Límite de respuesta: Define la cantidad máxima de tokens que el modelo puede emitir por respuesta. Por defecto, si el campo se deja vacío se asignarán 20 tokens como máximo a utilizar en la consulta.
Chrome #
- Ejecutable Chrome: Define la ruta local completa dentro del agente hacia el archivo binario ejecutable de Google Chrome (ej.
C:\Program Files\Google\Chrome\Application\chrome.exe). - Ubicación de perfiles: Especifica la ruta de la carpeta de datos de usuario (User Data Directory) si deseas que STELA inicie Chrome utilizando un perfil con cookies o extensiones preconfiguradas.
Ejemplos de Uso #
Uso Rápido #
• Validación de Cambios en Calidad (QA):
Cuando estás construyendo o dando mantenimiento a un script y este empieza a fallar en un paso específico, no necesitas alterar la configuración de producción.
- Crea una configuración temporal llamada
Debug_Local. - Activa el Modo depuración y los selectores de Log Consola y Log Texto.
- Ejecuta el robot. La consola te mostrará el árbol completo de comandos ejecutados y las respuestas del sistema operativo, permitiéndote aislar el error en pocos minutos sin ensuciar los reportes oficiales.
•Pruebas de Regresión Express (Sin Interfaz):
Si necesitas verificar rápidamente que una actualización en el sistema web no rompió tus flujos principales, edita tu configuración Default_Headless y activa la Ejecución headless de navegadores.
El robot ejecutará todas las tareas en segundo plano a máxima velocidad, liberando la pantalla de la máquina y entregándote un veredicto en una fracción del tiempo habitual.
Uso Avanzado #
• Paso de Ambientes Dinámico (Ciclo de Vida del Robot):
El mayor beneficio de este modelo es la capacidad de cambiar de entorno durante el flujo. Imagina un proceso que extrae datos de clientes desde una base de datos de pruebas (SQLSERVER) y luego debe impactarlos en el sistema real. Puedes definir dos configuraciones: Entorno_QA y Entorno_Prod.
• Estrategia de Pruebas Multi-Plataforma (Omnicanalidad):
Si tu empresa cuenta con un flujo que inicia en la web y termina en una app móvil (o viceversa), puedes diseñar una configuración llamada Web_Desktop (con parámetros específicos de Chrome) y otra llamada Mobile_Android (con tus parámetros de Mobile como AppPackage, AppActivity y UDID).
El robot iniciará su recorrido interactuando con la web en la primera configuración y, cuando el flujo lo requiera, invocará el comando «Configuración» para saltar al entorno móvil de manera orgánica, sin necesidad de particionar la automatización en dos proyectos separados.
• Optimización de Infraestructura para Ejecuciones Masivas:
Para robots que procesan miles de transacciones, crea un perfil optimizado llamado Procesamiento_Batch. En él, desactiva Imagen en evidencia, Video en evidencia y los logs secundarios (Log XML, Log Consola y Log TXT).
Al hacer esto, reduces drásticamente el consumo de memoria RAM, previenes cuellos de botella por lectura/escritura en el disco duro del servidor y disminuyes el peso de los reportes finales, asegurando ejecuciones limpias y ultra rápidas.
Errores Comunes y Soluciones #
- El robot se conecta a la Base de Datos equivocada durante el flujo
- Causa: Olvidaste arrastrar o invocar el comando «Configuración» en el lienzo del robot para indicarle al agente en qué momento exacto debe cambiar de perfil. Por defecto, si no se especifica el comando, STELA iniciará siempre con la configuración marcada como «Default».
- Solución: Asegúrate de colocar el comando «Configuración» al inicio del flujo o justo antes de realizar la acción que requiere las nuevas credenciales de base de datos (SQL/NoSQL).
- Las automatizaciones de una ejecución en cadena heredan una configuración equivocada
- Causa: Los cambios aplicados mediante el comando «Configuración» afectan el estado global del robot a lo largo de todo el flujo, no solo a la automatización individual donde se seleccionó.
Si tienes una ejecución con tres automatizaciones en cadena (1, 2 y 3), y la primera cambia el perfil de «Default» a «Otra_Config», las automatizaciones 2 y 3 continuarán usando «Otra_Config» de manera heredada al arrancar si no especificas otra cosa, ya que STELA no realiza un reseteo automático al pasar de una automatización a otra. - Solución: Establece como regla de diseño obligatoria colocar el comando «Configuración» en la primera línea de cada una de tus automatizaciones. Al forzar la selección de configuración deseada al inicio de cada script (ya sea apuntando explícitamente a «Default» o a cualquier otra), te aseguras de que cada módulo de la cadena corra exactamente bajo el entorno que necesita, bloqueando cualquier herencia accidental del proceso anterior.
- Causa: Los cambios aplicados mediante el comando «Configuración» afectan el estado global del robot a lo largo de todo el flujo, no solo a la automatización individual donde se seleccionó.
- Fallas de «Elemento no encontrado» al cambiar entre entornos rápidos y lentos
- Causa: El entorno de Desarrollo o QA suele responder más lento que el de Producción. Si usas los mismos tiempos de espera para ambos, el robot fallará por Timeout en los entornos de prueba.
- Solución: No alteres el script. Ve al modal de la configuración específica (ej.
Entorno_QA) y aumenta el Tiempo de espera por defecto (#) o la Espera inicio aplicación (#). Cuando el robot se mueva a producción con su respectivo perfil, volverá a utilizar tiempos más dinámicos y ajustados.
- El robot se detiene bruscamente con errores de memoria (Out of Memory) en procesos pesados de IA
- Causa: Al activar funciones avanzadas como el Procesamiento AI de HTML o Procesamiento AI de Imágenes, o al consumir modelos de lenguaje (ChatGPT/Gemini/Anthropic), el consumo de recursos de la máquina virtual se eleva considerablemente.
- Solución: Dirígete a la sección de Configuración Global del proyecto (parámetros transversales) e incrementa los valores de Memoria inicial JVM y Memoria máxima JVM (por ejemplo, asignar
1024de inicial y4096de máxima, dependiendo de las capacidades del entorno ejecutor).
- Errores de Autenticación o Tokens vencidos al interactuar con servicios en la nube (Jira, Azure, AWS)
- Causa: Se están compartiendo o sobreescribiendo credenciales obsoletas entre diferentes ejecuciones, o bien se modificó un token en el servidor de STELA pero el agente local no se enteró.
- Solución: Valida que las claves, API Keys o paths de archivos (como el JSON de Autenticación BigQuery o credenciales de Gsuite) estén cargados de manera independiente en cada perfil correspondiente. Si estás trabajando sin conexión a internet, recuerda activar el Modo de descarga Offline en la Configuración Global y volver a descargar el robot para forzar la actualización de los componentes de seguridad.